Executive Summary
Standard Retrieval-Augmented Generation (RAG) offers a quick start for LLM applications but consistently fails when faced with real-world complexity. The path from a working demo to a reliable production system depends on moving beyond generic RAG to a tailored, domain-specific retrieval of knowledge.
Moving from traditional RAG to knowledge graphs helps with the retrieval, but “off the shelf” GraphRAG drastically lose the recall as soon as the size and/or the complexity of the corpus grows. A Knowledge graph provides a much denser representation of knowledge, but even that rapidly shows limitations when we use "off the shelf" tools.
In this note, we demonstrate how a custom-built knowledge graph is the key to unlocking high-fidelity information retrieval needed in most useful applications and business use cases.
We validate our approach using a direct comparison with two of the most popular "off the shelf" Graph-RAG tools that many companies use when they get started. Using an identical text corpus — a dense summary of the Harry Potter plot — we benchmarked these GraphRAG tools against our own custom extractor. The performance gap was significant:
Our approach yielded over 4.2 times more signal from the same source text. This isn't just a marginal improvement; it's the difference between a superficial demo and a system that possesses a genuine understanding of its knowledge domain. This note details the architectural reasons for this gap and provides a blueprint for building retrieval systems that deliver production-grade performance.
- Neo4j SimpleKG found 15 relationships.
- LightRAG found 16 relationships.
- Our custom-built, narrow-domain extractor found 83 relationships.
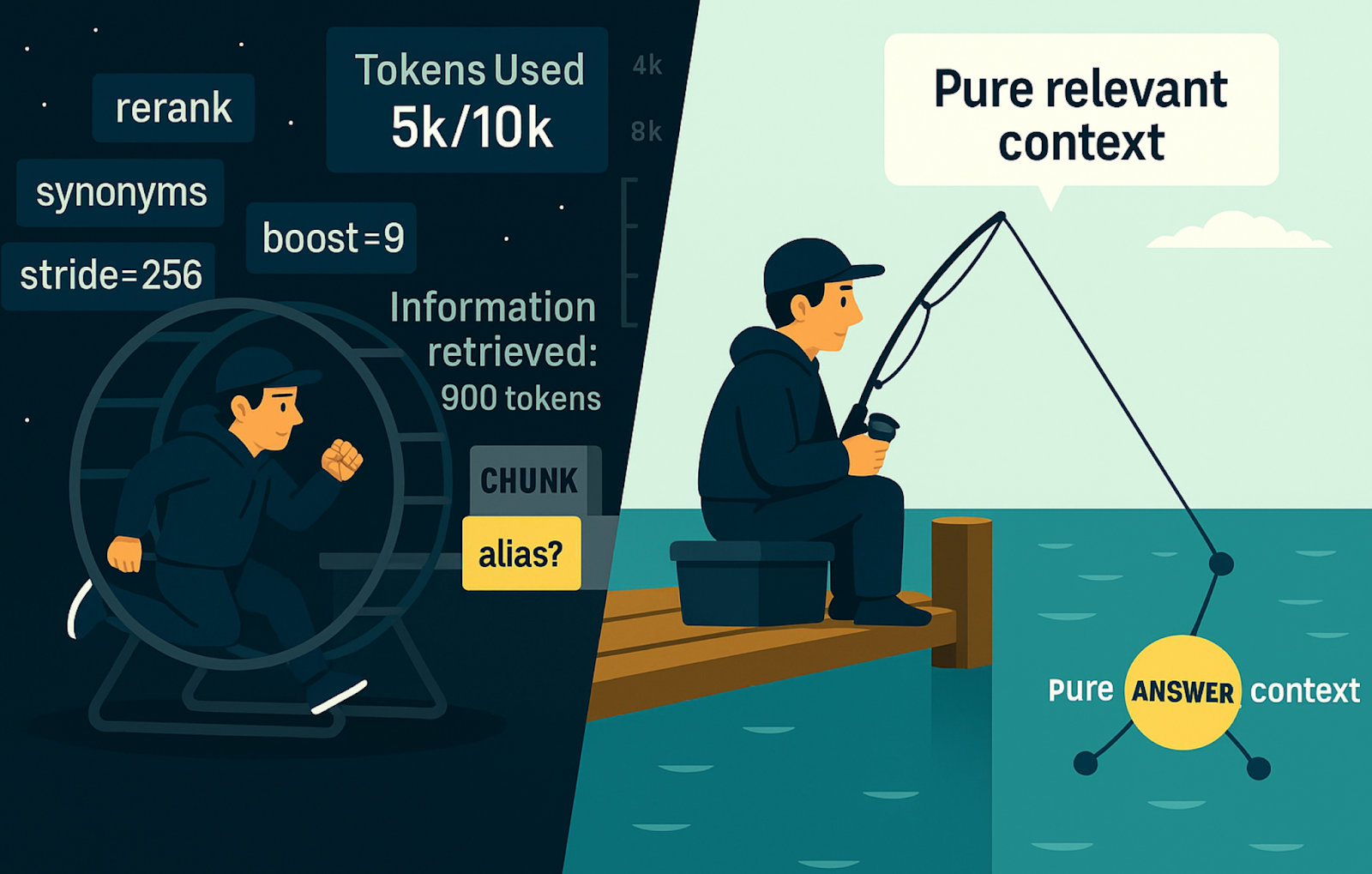
A Quick Recap on RAG
Information retrieval has become the backbone of almost every LLM application. Information retrievers help LLMs see knowledge beyond their training data, and hence are used to customize LLM applications for diverse use cases.
RAG systems work by chunking your corpus into bite-sized pieces, then retrieving the most relevant chunks for each query. It's become the go-to pattern for grounding LLMs with external knowledge, so much so that people have started using the terms knowledge retrievers and RAGs interchangeably.
Basic RAG systems work in demos but rarely scale with complexity. They can easily list 10 spells from Harry Potter when you ask about them, but often can't connect that Voldemort and "He-Who-Must-Not-Be-Named" refer to the same character. This isn't a quirk — it's a structural limitation of sequential knowledge fragmentation.
RAGs have gained popularity due to their simplistic design and quick results for a curated corpus. However, a demo needs to work with a few cases in the right environment. But an LLM application needs to create value consistently across dynamic scenarios. This is where most people (and teams in a hurry or under pressure) get stuck in cycles of cramming corner cases into ad hoc patches, padding chunks with synonyms, and hoping embeddings rank the right chunk high enough to be selected for the context to make sense.
The Limits of Traditional RAG
To understand why tailored retrieval is necessary, we first need to appreciate where the standard approach shines and where it falls short.
Where Traditional RAG Works
Traditional RAG works when:
- Facts live within single chunks: Answers are contained in one paragraph/page; no chunk hopping.
- Examples: Reset Okta password; travel policy cap (e.g. travel policy for a particular country)
- Cross-document reasoning isn't required: A single source is enough to answer the question; there is generally no need to stitch multiple sources together and reason.
- Examples: DevOps runbook: How to restart service X; How to clear stuck jobs of type Y. Support SOP: refund eligibility for cohort XY; RMA steps
- Indexing cost matters more than recall: Cases when we want to ingest a large corpus at a low computation cost; low recall generally doesn't matter.
- Examples: Product review aggregation where processing massive review datasets for sentiment analysis requires cost-effective ingestion over perfect recall. Edge/SMB deployments with tight latency/budget; lightweight pipelines over complex ETL.
- Missing some patterns is acceptable: Near-misses are fine; edge cases escalate to humans.
- Examples: Auto resolution of support tickets: 70–85% coverage reduces total tickets generated; escalated edge cases are handled by support executives. Marketing/enablement search: find slide or blog; near-hit is acceptable.
Where Traditional RAG Breaks
The simplicity that makes RAG effective in the above scenarios becomes a liability as complexity grows. The core issues are:
- Chunk-size sensitivity: Retrieval quality depends heavily on window size and stride; critical facts are often split across chunk boundaries.
- No structure: Vectors capture semantic proximity, not explicit associations like roles, types, hierarchies, or chronology.
- Scaling pain: As a corpus grows, top-k retrieval starts to favor frequently used words over rare but critical evidence.
- Redundant context: Chunking forces topics of interest to become entangled with peripheral content, naturally introducing irrelevant material and noise.
Solving the Devil's Details: From Problems to Building Blocks
Abstractions are one of humanity's greatest gifts to software engineering. But knowledge retrieval is a different beast entirely. It's intensely personal to each domain. You need fundamental building blocks you can reuse, but they must bend to the will of your specific domain—not force your domain to conform to their generic assumptions.
The following sections map the common, high-level problems of generic retrieval to the foundational solutions required to overcome them.
Problem: Drowning in Noise and Hitting the Context Ceiling
Consider a software development company planning a release. Their AI assistant is fed a stream of information from meeting transcripts and code documentation. A standard RAG-based retriever sees this as a flat collection of text chunks, making it difficult to isolate the signal (relevant project guidelines) from the noise (all the other topics discussed).
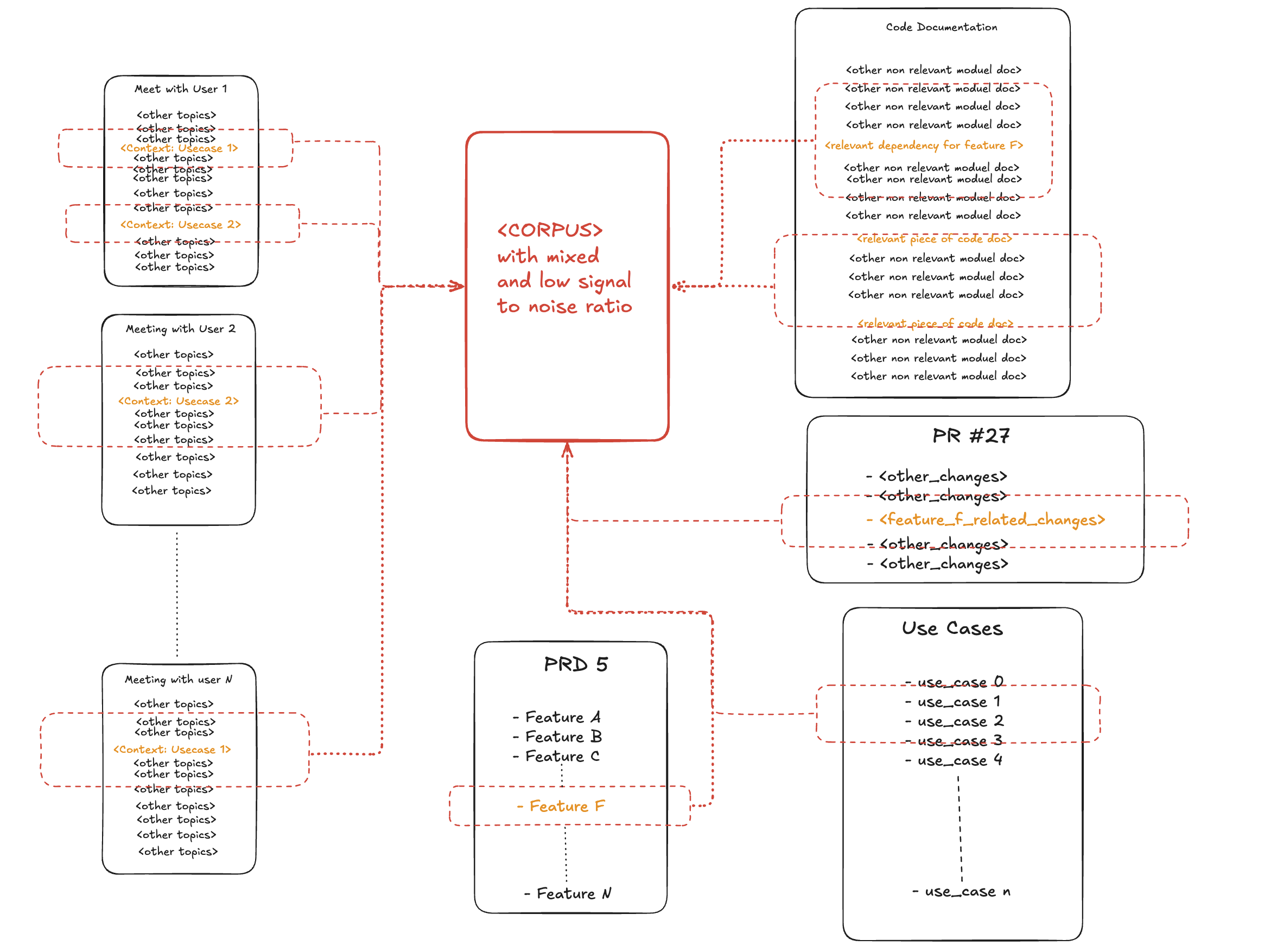
Take a topic, say "what are the specs for Feature F?" spread out across a document(s)—mentioned in the introduction, detailed in some meeting(s), referenced in the appendix. Traditional chunking retrieves all three sections. You feed the LLM ~10,000 tokens to extract ~100 units of information. The signal-to-noise ratio is a dismal 1:100.
This matters because every token spent on noise is an opportunity cost. If you have a 10,000-token context window and your signal-to-noise ratio is 10%, you're getting ~1,000 tokens of useful information. Bump that ratio to 90%, and suddenly you're working with ~9,000 tokens of useful capacity. In the best case, noise simply wastes context space. More often, it creates opportunities for hallucination.
Solution: A Relationship-First, Domain-Aware Knowledge Graph
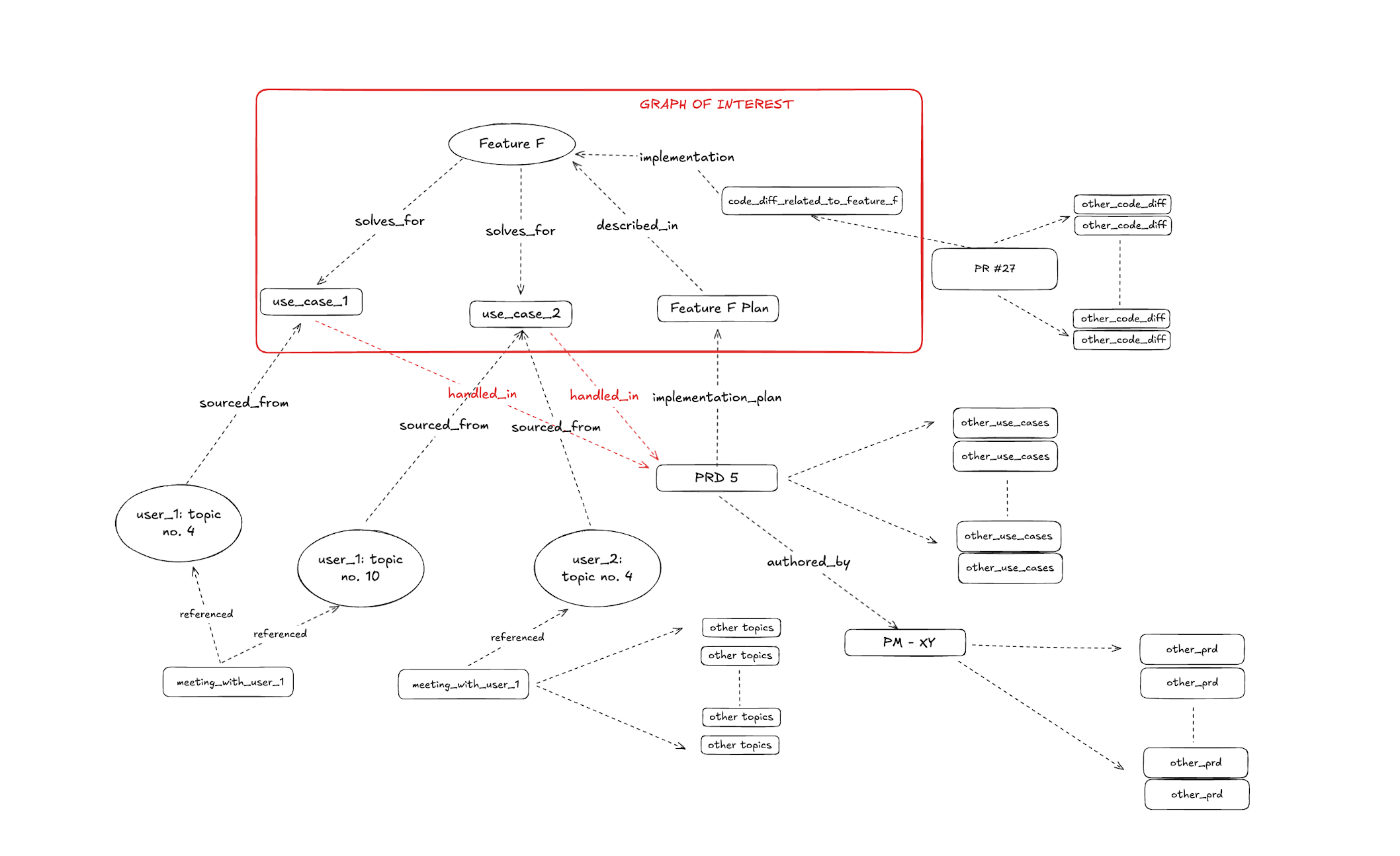
The solution is a Relationship-First Indexing approach. Instead of treating text as the primary artifact, we treat relationships as the fundamental unit of knowledge. Knowledge graphs represent information as a connected web of nodes (entities) and edges (relationships), modeling how concepts relate to each other.
The same example of software company discussed above — but with semantic relationships connecting the modules, the retrieval becomes much more pin-pointed. We represent that same information as a graph:
- PM → WROTE → PRD
- PRD → PROPOSES → Feature F
- Feature F → SOLVES_USE_CASE → Use case 1, Use case 2
- Use case 1 → SOURCED_FROM → Meetings with users 1,2,3
- Feature F → IMPLEMENTED_IN → PR no 27
- … and so on
The relationships presented have a solid information density. Roughly 30 tokens carry the same information. Graph retrieval yields ~90% signal density.
We evaluated popular tools like Neo4j Knowledge Graph pipelines and LightRAG and quickly discovered that while they get a demo up and running, they can't handle domain-specific nuances. General-purpose tools are optimized for broad applicability, but when accuracy and recall matter, their generic abstractions become limitations.
High-quality retrieval depends on two things: speaking the domain's language (the right entity types and roles) and using precise, directional relationships. If you don't cater to the domain-specific semantics, you end-up with generic relationship extractions. You lose the very specificity that makes knowledge graphs powerful. However, some information is more naturally expressed as plain text. This is where having custom building blocks shines—they give you the best of both worlds. Instead of forcing everything into graphs or keeping everything as text, a smart system uses both strategically, storing unstructured text as a property on a node or relationship.
Problem: Fragmented Identity and Inconsistent Schemas
A subtle but devastating failure mode of generic extractors is their inability to handle identity and classification consistently. When "Dr. Jane Smith", "Jane Smith", and "J. Smith" are treated as separate people, the knowledge base becomes fragmented and unreliable. Likewise, when one tool labels "Google" an "Organization" and another labels "Microsoft" a "Company," the schema devolves into chaos.
Solution: Intelligent Deduplication and Schema Reinforcement
First, a system needs Intelligent Entity Deduplication. This is more than simple string matching. A robust system uses a multi-layered approach, combining embedding similarity with LLM-driven analysis to confirm if two mentions refer to the same real-world entity. Without this, information about the same person or concept gets scattered, and you can never get a complete picture.
Second, a system needs Schema Evolution with Consistent Reinforcement. A rigid schema—"Person", "Company"—is too brittle for the real world. A zero-shot LLM, however, can easily create chaos. The optimal solution is a form of rolling context window for schema generation. The system maintains a live, in-memory representation of the current schema. For each new document, it presents this existing schema to the LLM as part of the prompt, instructing it to conform where possible and only introduce new entity or relation types when absolutely necessary. This creates a living index that adapts and grows in sync with the domain it serves, reducing schema drift and maintaining consistency.
Problem: Missing Context, Authority, and Scope
Consider a management consultant who interviews dozens of people. When asked "What's our recommended approach for digital transformation?", a generic system might surface a casual comment from a junior employee that contradicts a well-researched McKinsey report—simply because the transcript ranked higher. A generic extractor treats all relationships equally. In chemical manufacturing, a safety guideline mandatory for Product A might be catastrophically wrong for Product B. Generic extractors miss these crucial scope constraints.
Solution: Edge-Level Provenance
Every relationship in the knowledge graph must carry edge-level provenance—explicitly linking extracted facts or connections back to their source evidence. The statement "McKinsey's 4-step digital transformation is our starting point for client engagements" should be indivisibly linked with the document ID, the specific text chunk, and any other relevant metadata (like author, date, or confidence score). This allows a retriever to weigh sources, check for scope, and understand the temporal relevance of information before passing it to an LLM, preventing it from making critical errors.
Problem: Fragile Pipelines and Wasted Effort
Real-world information flows continuously. A system that requires a full reprocessing for every new document is inefficient and will always be out of date. Furthermore, long-running extraction jobs can fail mid-process, losing hours of expensive LLM calls. You will no doubt see this when you use demo/MVP tooling, since it is not built to handle any of these problems. Traditional software engineering expertise is needed here, with an awareness of how this applied to LLM-driven operations.
Solution: Incremental, Crash-Safe Ingestion
A robust knowledge extraction system must support incremental ingestion—processing only new or changed content. This ensures the knowledge base stays fresh without unnecessary latency or compute costs. To protect against failures, the pipeline needs Crash-Safe State Management. A database-inspired Write-Ahead Log (WAL) is a perfect fit. Every mutation gets logged before it's applied. On crash, the system simply replays the WAL to reconstruct its exact state, with incremental checkpoints enabling full resumability without rebuilding from scratch.
The Challenge of Scale
As you increase the knowledge base, chunk_size / corpus ratio goes on decreasing. As the total text (corpus) grows, or as we cut it into smaller pieces (chunks), each idea gets split across more pieces. The useful pieces end up surrounded by many more unrelated but semantically closer pieces, so it's less likely that the right pieces show up together when we search. That makes it harder to pull the full idea back into one place, and the useful signal gets diluted by extra noise.
Increasing the corpus can only ever give you a similar or worse retrieval signal to noise ratio. In fact, it will practically always go down. Imagine an example of some content about the Himalayan mountains. As we increase the number of inputs to our corpus, there is an increasing chance of irrelevant topics seeping close in similarity to Himalayan mountains. For example – Himalaya the FMCG, or himalayan packaged drinking water etc. These topics might not be related to the mountains but still might be closer in the embedding space. Hence increasing the corpus at best has net neutral effect, and in a realistic scenario often lowers the signal to noise ratio for semantic searching over chunks.
As the corpus grows, we rely on the second order metrics like recall and accuracy to gauge the indexing quality. One way to test the robustness for a graph extractor linking concepts together without bloating the corpus is to decrease the chunk size instead and see how well it still connects the appropriate concepts. So we did this experiment: We kept the corpus fixed, but decreased the chunk size to 3-4 lines. The extractor we built using the principles above is still able to link the concepts together in a constrained environment owing to the fundamental building blocks.
This test is directional rather than deterministic. It signals expected behavior trends at scale.
But Isn't This Harder? The 'Build vs. Buy' Trade-off
A tailored retriever, by definition, requires more upfront design and effort than an off-the-shelf RAG library. It's a fair question to ask if the investment is worth it.
Our experience shows that the initial, visible effort is rarely the real cost. The true cost of a generic approach emerges over time: it's the endless cycle of patching corner cases, the wasted engineering hours trying to force a simplistic model onto complex reality, and the significant business risk of an AI that confidently gives incomplete or incorrect answers.
The choice isn't between an easy path and a hard one. It's between building a reliable, long-term asset that understands your domain, versus maintaining a brittle demo that never truly leaves the lab.
Case Study: Putting Theory into Practice with Harry Potter
Now that we've laid out the context and the common failure modes, we designed a focused experiment to see how off-the-shelf graph extraction pipelines indexes a given context, and what kind of questions can we expect it to answer.
To begin with, we took a TL;DR of the Harry Potter plot. This is a good test case because it's a small enough context that we can manually verify the results, and it's a dense enough context that we can expect to see relationships coming out of it.
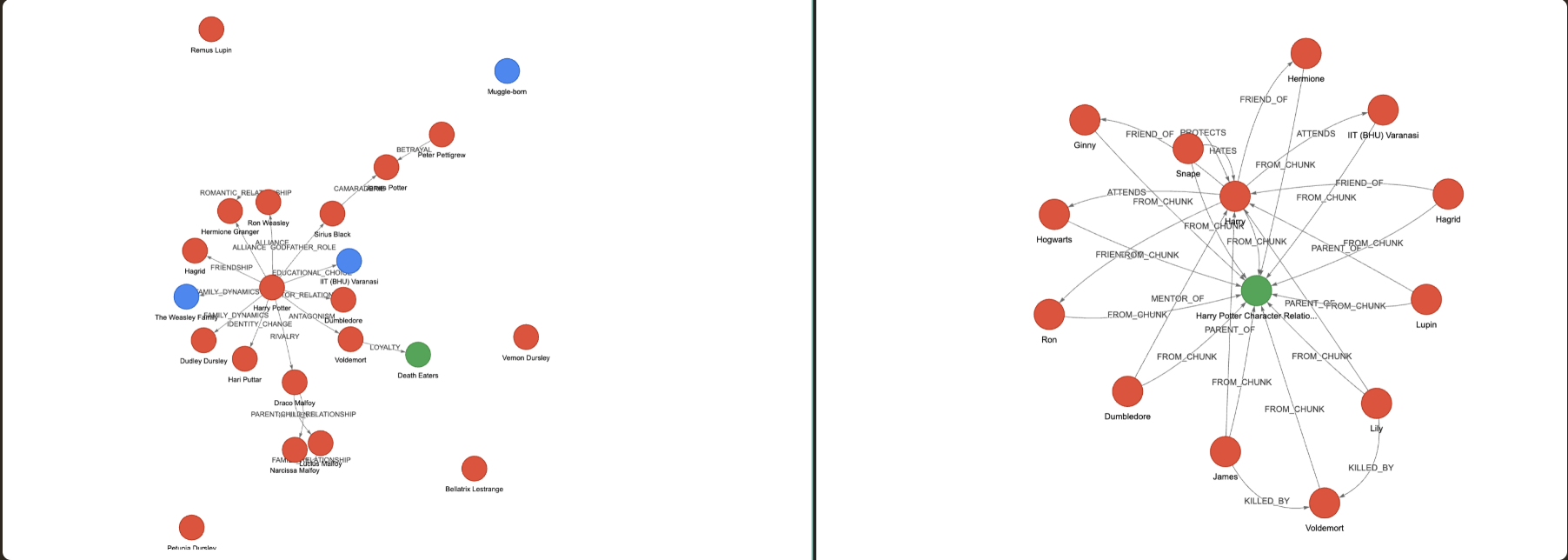
We ran it against popular graph extractors. Below are the results from the top two systems.
Neo4j SimpleKG Triplets
Total: 15 relationships
Harry → FRIEND_OF → Ron
Harry → FRIEND_OF → Hermione
Harry → ATTENDS → Hogwarts
Ron → FRIEND_OF → Hermione
James → KILLED_BY → Voldemort
James → PARENT_OF → Harry
Lily → KILLED_BY → Voldemort
Lily → PARENT_OF → Harry
Dumbledore → MENTOR_OF → Harry
Hagrid → FRIEND_OF → Harry
Arthur → PARENT_OF → Ginny
Molly → PARENT_OF → Ginny
Snape → HATES → Harry
Snape → PROTECTS → HarryLightRAG Triplets
Total: 16 relationships
Harry Potter → FRIENDSHIP → Ron Weasley
Harry Potter → FRIENDSHIP → Hermione Granger
Harry Potter → ANTAGONISM → Voldemort
Harry Potter → GUARDIANSHIP → Sirius Black
Harry Potter → CONFLICT → Draco Malfoy
Harry Potter → FAMILY → Arthur Weasley
Harry Potter → FAMILY → Molly Weasley
Harry Potter → GUIDANCE → Albus Dumbledore
Harry Potter → COMPLEXITY → Severus Snape
Ron Weasley → PARTNERSHIP → Hermione Granger
Voldemort → ANTAGONIST → Death Eaters
James Potter → FAMILY → Lily Potter
James Potter → BETRAYAL → Peter Pettrew
Draco Malfoy → ASSOCIATIONS → Lucius Malfoy
Lucius Malfoy → FAMILY → Narcissa MalfoyLooking at these triplets, the following issues become immediately apparent:
- Missing critical relationships: We'd expect to see many more connections beyond the main characters.
- Schema inconsistency: Neo4j extracts only first names, which would be disastrous at scale. LightRAG extracts full names, but its relationships are generic and lack directional, actionable meaning.
- Limited cross-entity reference: Neither system effectively links entities mentioned in different parts of the text.
We want to emphasize that our primary evaluation uses this compact passage. If a system can't handle a dense but bounded input, it's not likely to shine with more data.
For full transparency, reach out to us and we would be happy to send the detailed logs with direct, head-to-head comparison of outputs across systems, highlighting where each one succeeded or failed at entity deduplication, schema consistency, cross-document links, and relationship extraction.
Comparison Summary
| Feature | Custom_ND | Neo4j SimpleKG | LightRAG |
|---|---|---|---|
| Relationships (Harry Potter) | 83 | 15 | 16 |
| Entity deduplication | ✓ Embedding + LLM | ✗ Weak | ✗ Weak |
| Schema consistency | ✓ Rolling context | ✗ Zero-shot | ✗ Co-occurrence |
| Cross-doc merging | ✓ Global registry | ✗ Linear chains | ✗ Topic clusters |
| Crash recovery | ✓ WAL | ✗ | ✗ |
| Provenance | ✓ Edge-level | ⚠ Chunk-only | ⚠ Limited |
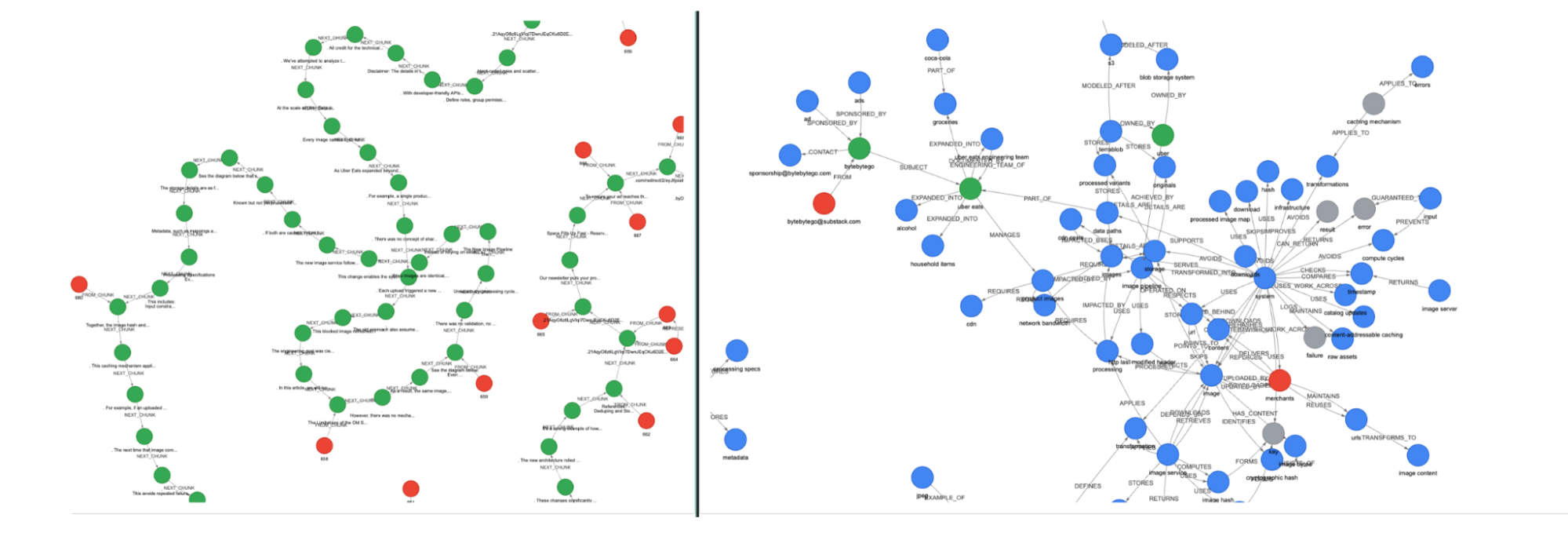
Graph visualizations (LightRAG and SimpleKG), with visual representation of the triplets mentioned above:
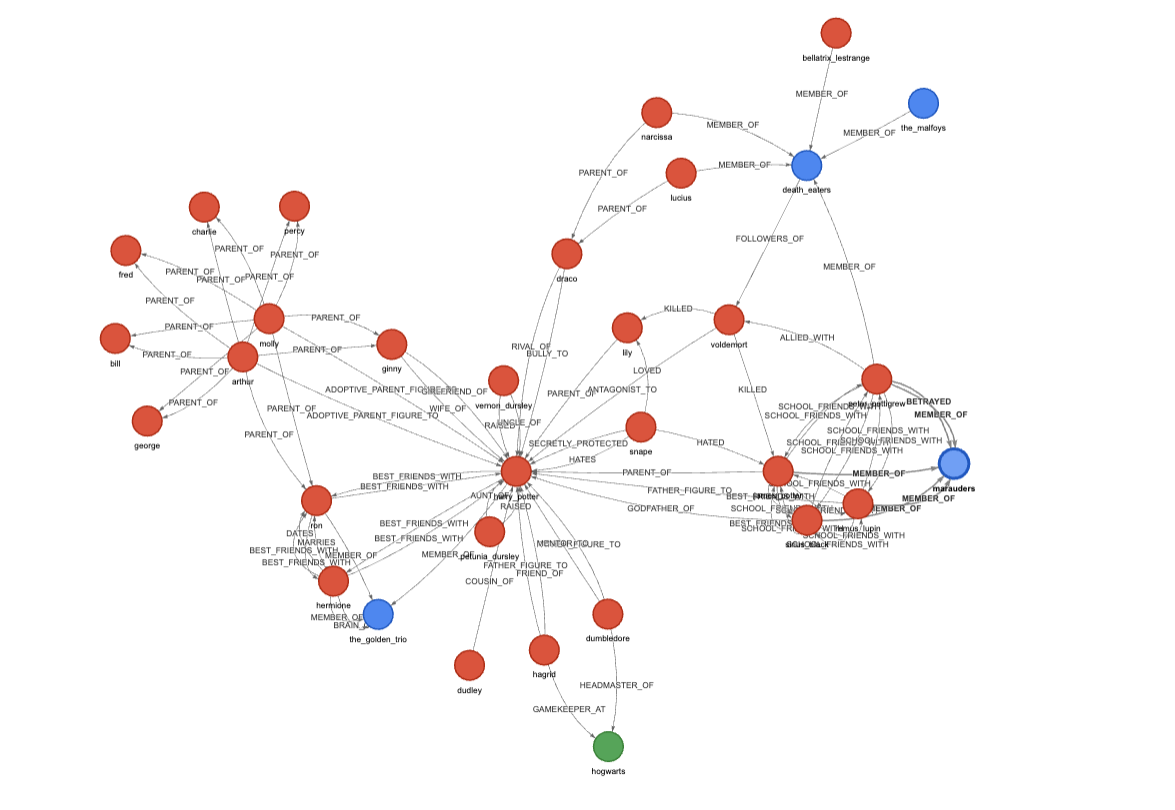
Our home-brewed customND, showing a much denser capture and representation of knowledge:
Deep Dive 1: The Marauders
Let's look at a specific instance. The source text contains:
"James Potter, Sirius Black, Remus Lupin, Peter Pettigrew were school friends... Peter betrayed them to Voldemort"
Our Custom_ND triplets correctly identified the group and the betrayal:
james_potter → [MEMBER_OF] → marauders
sirius_black → [MEMBER_OF] → marauders
remus_lupin → [MEMBER_OF] → marauders
peter_pettigrew → [MEMBER_OF] → marauders
peter_pettigrew → [BETRAYED] → marauders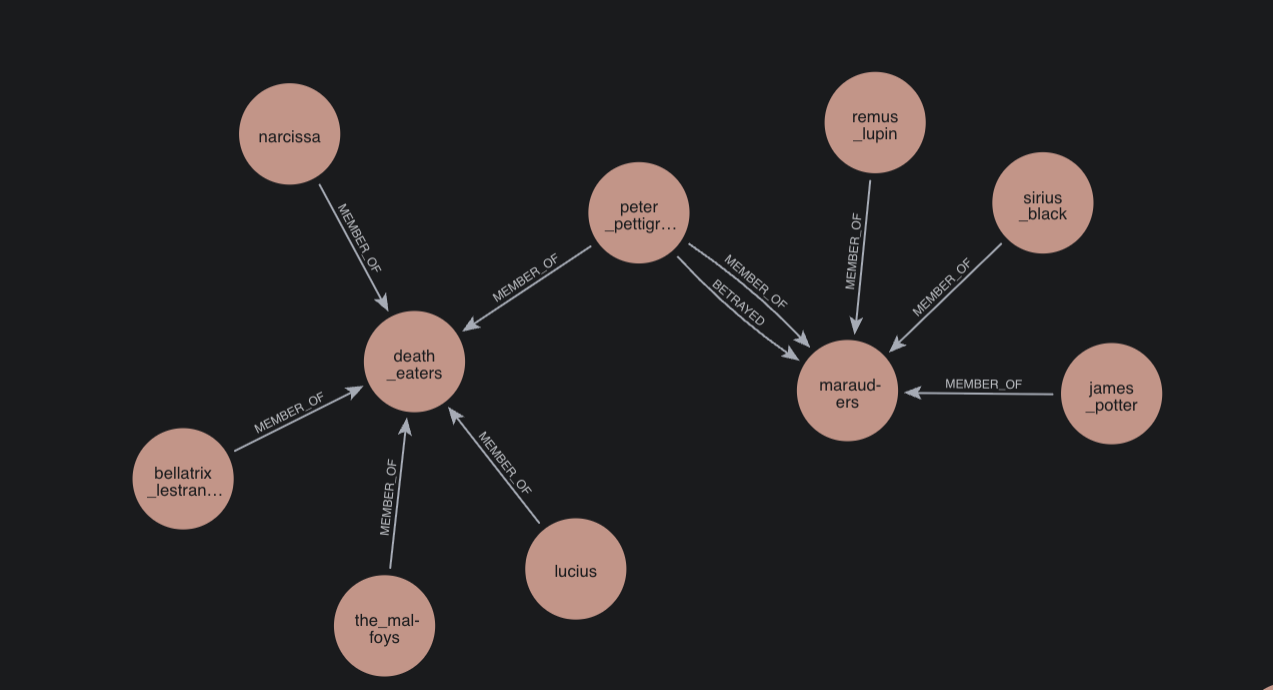
Neo4j SimpleKG extracted no relationships for this instance.
LightRAG captured only a single, less specific relationship:
- james potter → BETRAYAL → peter pettigrew
Deep Dive 2: Guardianship and Father Figures
Source text:
"Godfather: Sirius Black... Father figures: Dumbledore, Hagrid, Lupin"
Our Custom_ND triplets captured the specific roles:
dumbledore → [FATHER_FIGURE_TO] → harry_potter
hagrid → [FATHER_FIGURE_TO] → harry_potter
remus_lupin → [FATHER_FIGURE_TO] → harry_potter
sirius_black → [GODFATHER_OF] → harry_potter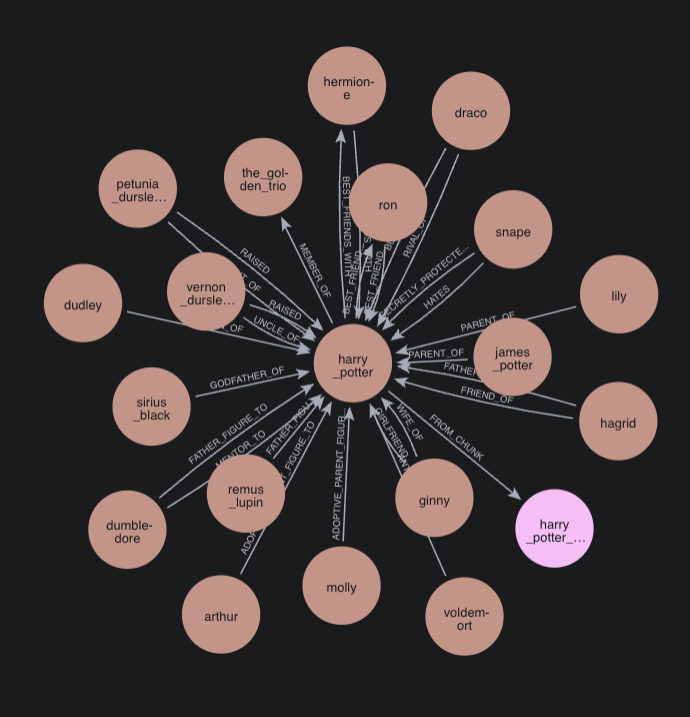
Neo4j and LightRAG extracted only generic, less precise relationships:
// Neo4j
dumbledore → MENTOR_OF → harry
hagrid → FRIEND_OF → harry
// LightRAG
harry potter → GUARDIANSHIP → sirius black
harry potter → GUIDANCE → albus dumbledoreConclusion: Stop Patching, Start Building
Traditional RAG is a powerful pattern for getting started with LLM applications, but it is just that—a starting point. The path from a simple demo to a production-grade system that consistently delivers value is paved with domain-specific nuance. As we've shown, generic, off-the-shelf tools, while useful for rapid prototyping, fundamentally lack the architectural components needed for high-fidelity information retrieval. They struggle with identity, context, and scale, resulting in a low signal-to-noise ratio that cripples the effectiveness of even the most advanced LLMs.
Building a custom, graph-based retriever isn't about chasing marginal gains; it's about shifting from a paradigm of patching and prompt-tuning a leaky abstraction to building a robust, resilient, and intelligent foundation. By focusing on fundamental building blocks—like intelligent deduplication, crash-safe ingestion, and edge-level provenance—you create a knowledge asset that truly understands your domain and can serve as the backbone for reliable, accurate, and powerful AI applications.